

I have a long-standing love/hate relationship with Jira. The product has an impressive level of power & flexibility that it can often be intimidating to users. Jira’s automation features are a great step toward changing this. The no-code implementation is really well done, striking a great balance of high-power, low-complexity.
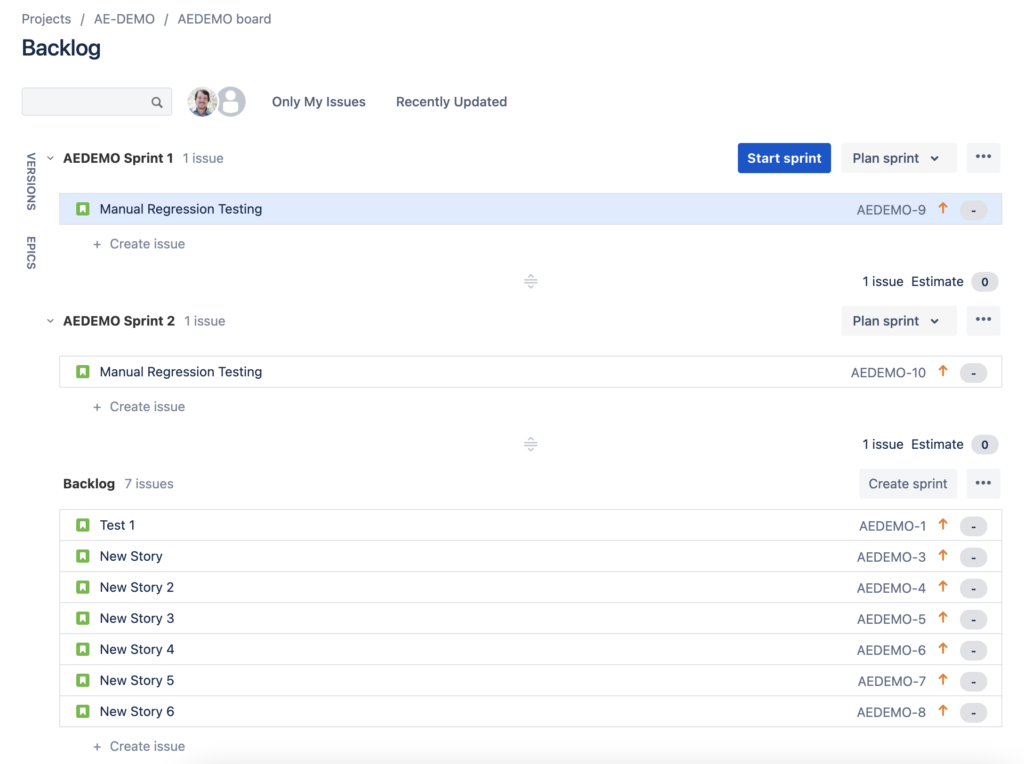
Recently, I wanted to ensure that every new sprint had a story in it to represent a manual regression testing step. Of course, I should automate this manual process, but that is a conversation for another post. In the meantime, however, we can ensure that the manual process gets scheduled for every sprint.
Let’s create a Jira automation rule that will create a “Regression Testing” Issue in every sprint that is created in a project.
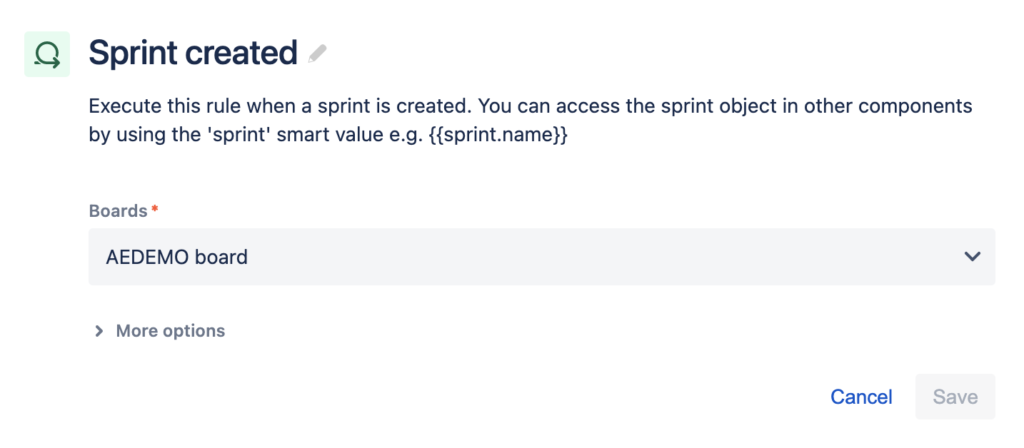
First, we’ll create a rule to trigger on sprint creation

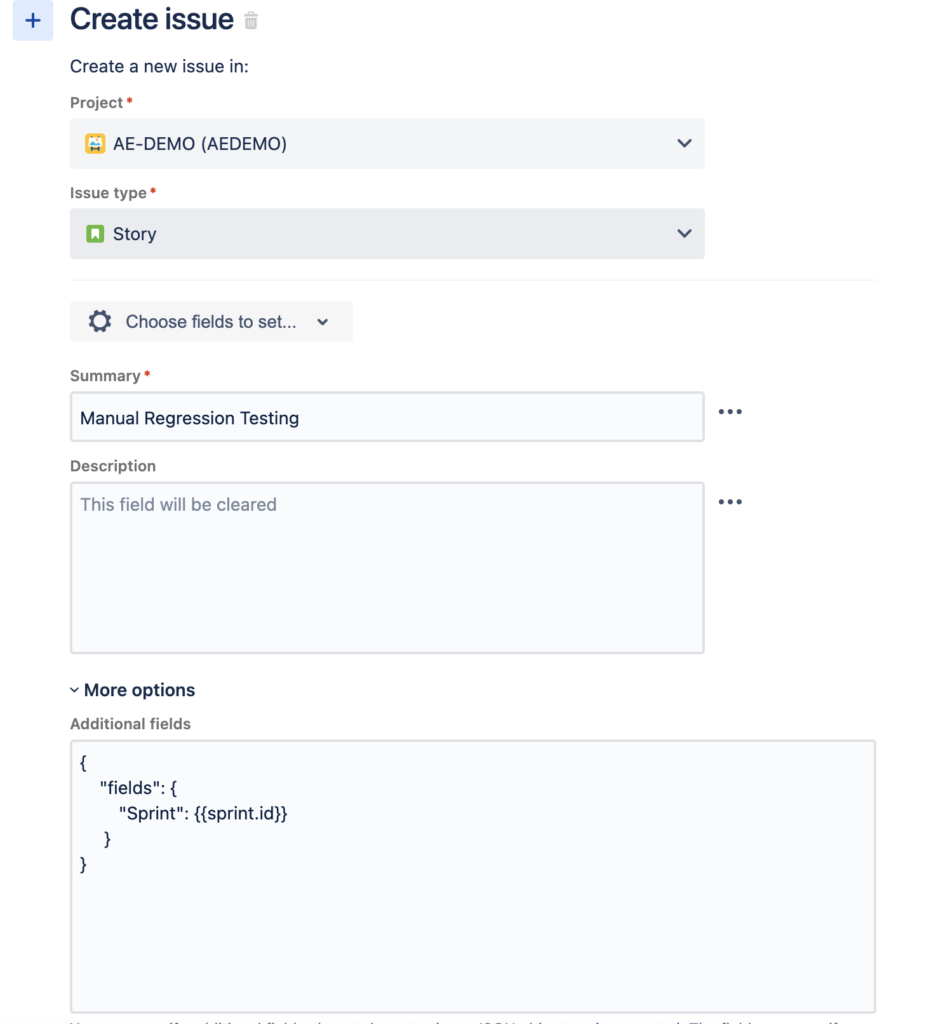
Then, we’ll add an “action” to create a new issue. We’ll use the {{sprint.id}} smart value to set the sprint on the issue.

Let’s test it out by creating a sprint (you’ll need to refresh to see the story).

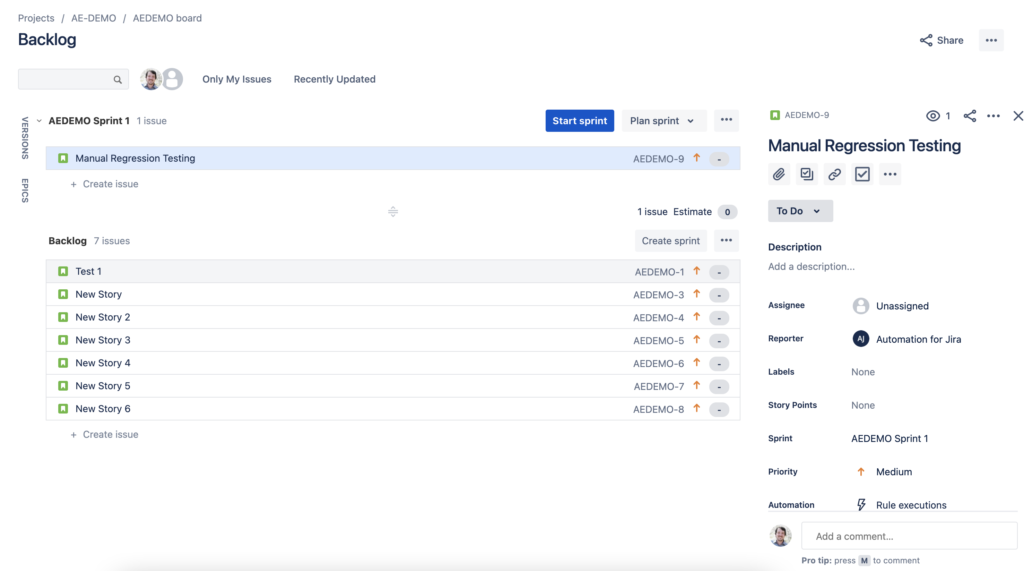
We’ve got a new sprint with a story in it. Success!
What if it failed? Plan B.
On occasion, the technique above won’t work. A Jira installation can become a complex web of plugins and side effects, and on occasion, I’ve encountered projects where the previous configuration doesn’t do the job. In this case, we can still make an automation rule that works. Instead of setting the sprint id on the initial issue create, we’ll create the issue, then edit it to move it to the correct sprint.
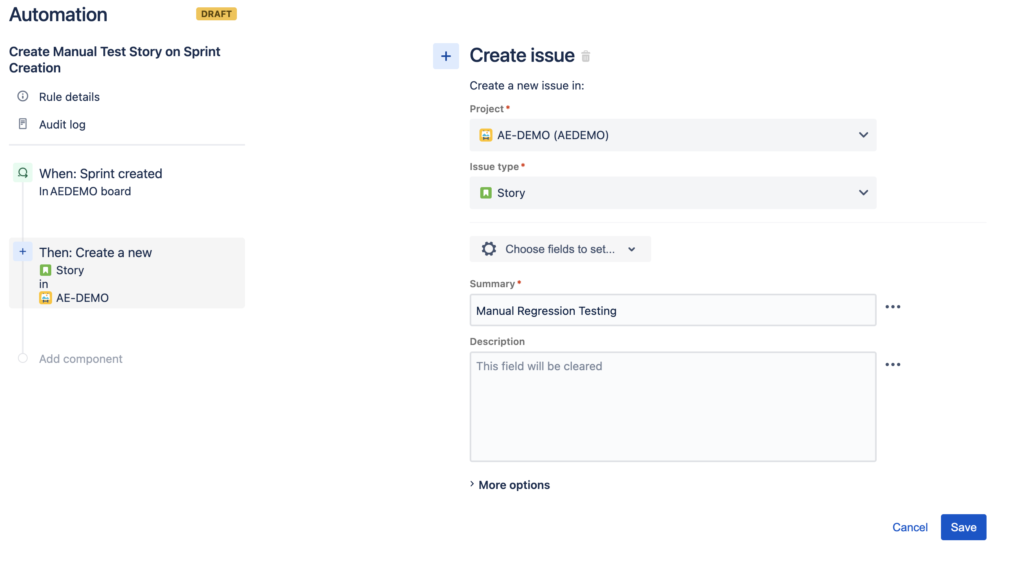
We’ll start by editing the “create issue” action so that it doesn’t attempt to set the sprint.

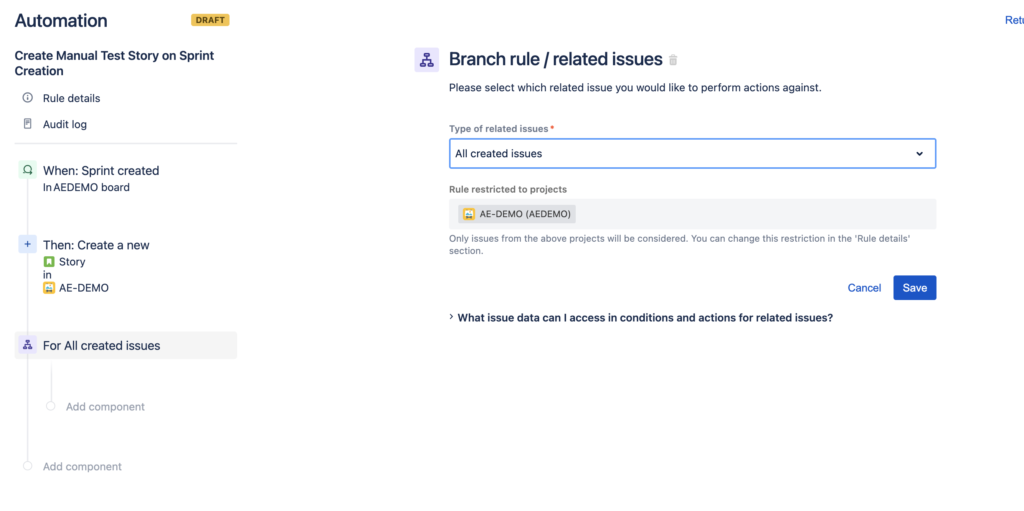
Next, create a “Branch Rule” to select the newly created issue

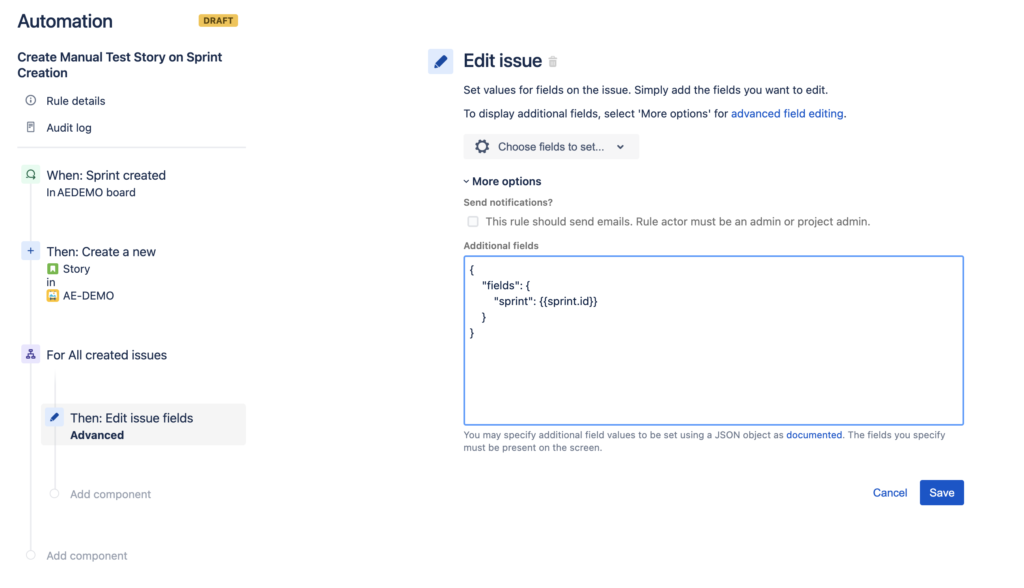
Now, we can create an action to edit the created issues, and set the sprint. The {{sprint.*}} smart values will still be available here.

Finally, we test it out (again, you’ll need to refresh after creating the sprint. Works this way too.